

Passive Data Collection vs. Proactive Monitoring: Analyzing Pump Motors to avoid Fires in a Live Environment
Sentrics enables you to widen the scope of data collection throughout your processes to provide a more complete view of the critical assets within your industrial environment. The Sentrics platform serves as a flexible and extensible tool to gather important information from a wide variety of cost effective sensors.
The process is simple:
- Collaborate with the Sentrics team to complete a site survey, and install new sensors as needed. The time from the beginning of Installation to receiving live data in the platform can be completed within as little as 15 minutes.
- Observe the signals and recognize new patterns around any identified “bad actors” with the help of our experts.
- Collaboration and tuning for approximately 30-60 days
- Collection of a wide variety of critical measures such as temperature, vibration or pressure can be used to baseline and diagnose changes in the health of the equipment.
- Begin to use this information to inform and set monitors to watch for certain conditions.
- Sentrics team will utilize their experience to provide to provide guidance on the configuration of these monitors as needed.
- Once a desired condition is met signaling the detection of a change in asset health, an alarm is sent.
- Alerts can trigger personalized notifications via email or text message or populate a record in your asset management or ticketing system to kick of existing internal processes in your current systems.
- The ability to configure escalation paths is also available.
In this article we discuss a proof of concept scenario in which data was collected via the Sentrics platform more passively, prior to implementation of more advanced analytics and proactive monitoring, by its end users. This approach closely resembles a reactive approach similar to those most common in industrial environments today – the equivalent of an occasional or irregular “spot check” that requires an element of being in the right place at the right time to diagnose changes in equipment health. This proof of concept scenario will illustrate how basic alarms allowed a facility to be made aware of a total pump failure (failure meaning the pump catching fire, melting down and going offline entirely) but was collecting all of the necessary data needed to set and enable more sophisticated alarms which suggests strongly that end users would have been alerted on the change in asset health before the failure to avoid this high cost and dangerous failure.
The Sentrics system was set-up in a matter of minutes and the process engineer and maintenance team had custom views of incoming data configured by the end of the hour. Definitions were set so the company can easily track and identify the parts they were monitoring.
In this scenario, even given the severity of the fire, the sensor continued to transmit readings after the burnout. Even when scrapped alongside the failed motor it reached a range of several hundred feet. In some cases, it is possible to spot a growing trend that leads to partial or total failure. In the case we’re looking at, some symptoms by the fault which emerged rapidly and could trigger alerts for action.
The Environment
An industrial chemical manufacturer installed the system to obtain a real-time view of different pump motors in an area of the process previously labeled a “blind spot” as not ability to collect data from these assets existed prior . The sensors were placed at key areas of the pump motors and chiller pipes with the goal to collect information, understand operating behaviors of these motors, and leverage the information to become more proactive on any required maintenance to avoid potential failures. Multiple points were setup to observe the flow of the coolant fluid as well as various points in the system. Vibration measurements were taken from both the motor and the pump that moved the fluid. Heat measurements were taken from 2 of the pumps and manifold which carried the coolant, as well as each of the motors.
This system operated as part of a cooling system and as a way to transfer coolant to a highly combustible area of the facility. Although this area of the process was not considered to be on the first line of critical assets, it was in fact vital to keeping other critical assets within the process online, yet the health and status of these assets were not being monitored in a real-time. The purified water pumps continuously through a series of pipes to a centrifuge then back to the chiller. The system is redundant, with four pumps. Operators need to know without a “site survey” and get ahead of any maintenance or repair that is needed. With this installation, sensors were placed on a number of motors and the corresponding pumps. Temperature sensors were also placed on several key points to track temperatures (ambient, cooling manifold, and motors).
The following views were taken directly from the Sentrics Platform. The first exhibit shows a dramatic temperature spike that broke 3 standard deviations from the typical cycle. These pumps routinely operate at a maximum of 50 degrees Celsius even during the summer months.
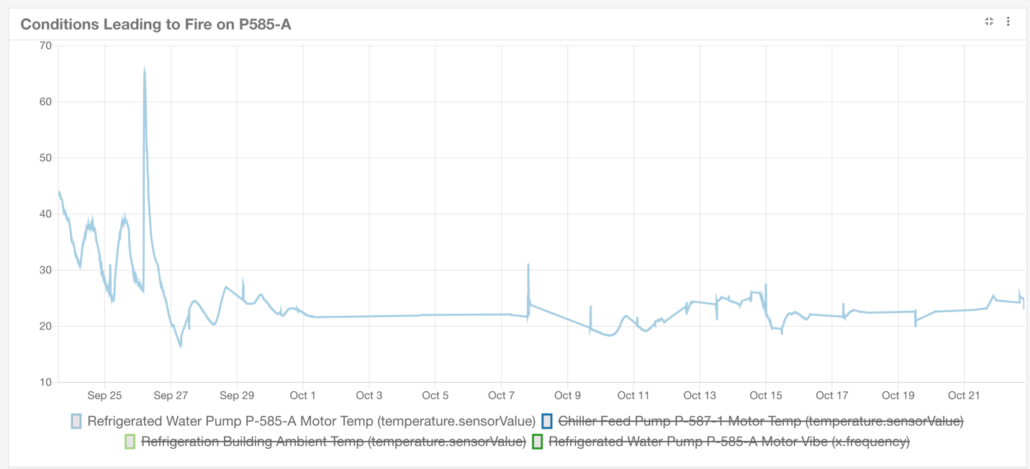
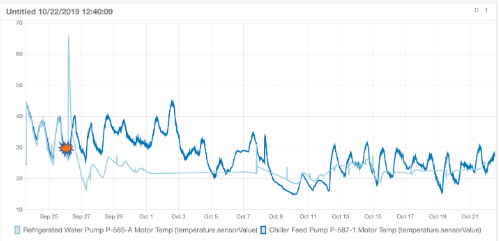
Through the collection of additional data points, a more broad view of the problem begins to take shape. Temperature of the healthy pump and the one which broke away show how far the temperatures deviated. This can be programmed into the system as the first way to identify a problem, but is more of a reactive technique.
When we add a third dimension to learn even more about the conditions that lead up to, and the state of the pump, temperatures appeared to revert back within normal operating range. Vibration signal (illustrated in green, below) showed a significant drop that had not been seen before. Within the next temperature cycle, the fault occurred. We also see the vibration signal drop below the normal operating range (operating frequency is 40 Hz). This shows a complete failure to where the pump is no longer running
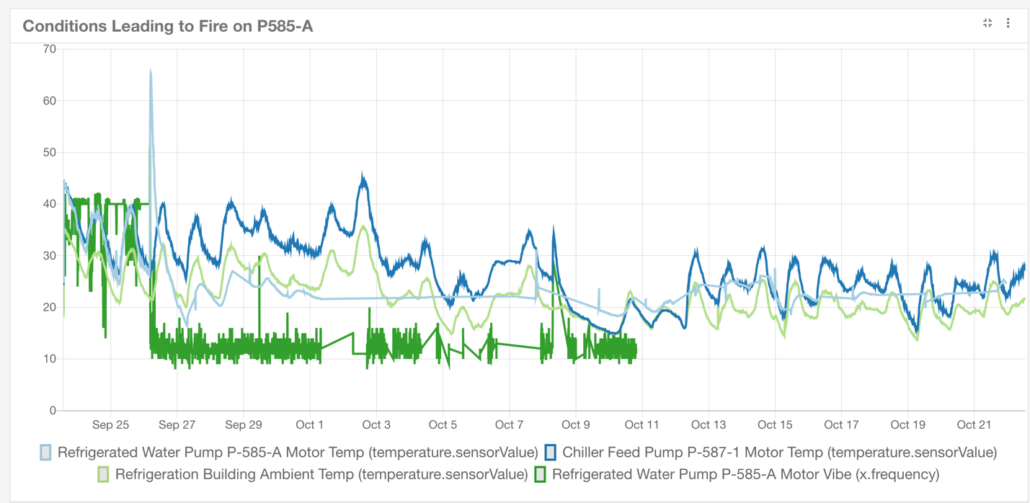
In this scenario, the failure detection kicked in towards the end of the cycle, but that was too far after the curve. This illustrates the point that leveraging even the most real-time systems, it’s important to put the right practices in place so the value of that data can also be surfaced in real time to initiate actions to mitigate potential failures, and disruptions to up-time. Keeping this information in mind, more sophisticated monitors can still be set that will watch for this condition across any of the other pumps remaining, which we know will identify the signal that happens prior to a failed state. With some warning and the ability to remotely cycle down the pump for inspection, a far less severe breakdown is achievable.
The Costs:
In this particular scenario the effects were costly:
Downtime: 36 Hours
Cost of Parts: $1,200
Cost of Labor: $2,280
Cost of Motor: $4,000
Estimated Product Loss: $125,000
Total Cost of Failure: $132,480
The net goal is to save on repair costs via enabling a more proactively ability to understand, assess, and maintain critical equipment investment. All things considered, the cost to implement and support Sentrics and proactive monitoring over 12 months in this small portion of this facilities process, totals less than 20% of the costs incurred by this single pump failure.
What Can We Learn From This Real-World Indication?
- The real-time data can aid in faster detection or preventative signals. In this era, the periodic planned maintenance cost time and do not provide the patterns needed to both detect and correct a problem before it becomes disastrous.
- You can quickly move from baseline to watching for alert conditions. This may sound obvious, but we find even the 1 hour or so needed to study and tune alerts often can be neglected. Having the ability to quickly set and reconfigure different scenarios, you can spend less time constantly monitoring (manually) and more time responding to timely, technology driven monitors and alerts.
- Leverage multiple factors (data inputs) to mitigate false alarms and be confident in your alerts.
- False alarms are the enemy of real problems
- This can take several iterations, but worth the extra time spent to prevent a more consistently prevent a total failure
- Apply lessons learned from a failed condition to future monitors.
- This system has a live monitor that will send an early warning
- Based on this data/scenario, our estimations are that at least 24 hours notice can be given
- Despite the common emphasis put on temperature data, this data alone would NOT have provided us with the required information to identify these issues.
- Use a secondary line of defense with an alarm as a reactive move.
- Example: The initial reading was cited at 4:15 – The vibration reading shows total failure didn’t occur until 6:48 am.
To learn how Sentrics can enable you to avoid disaster with proactive monitoring, contact the team at info@sentrics.io or give us a call at (630)866-6001.
– The Sentrics Team

